|
2012年に開催された大規模画像認識のコンペ ILSVRC(ImageNet Large Scale Visual Recognition Challenge)で AlexNet が圧倒的な成績で優勝して以来、ディープラーニングの手法が画像認識での主役に躍り出ました。それ以降、ILSVRC で ImageNet の画像を用いたモデルの開発競争が行われてきました。
ディープラーニングの手法はCNN (Convolutional Neural Network)を基礎としています。その初期代表モデルは LeNet と AlexNet でした。その後、畳み込み層を深くすればするほど学習精度が上昇するので、畳み込み層をより深くするモデルが登場しました。VGG16、VGG19 は畳み込み層の深さを16、19にしたネットワークモデルです。GoogLeNet は畳み込み層を22にまで拡大しました。そして、150層を超えるディープな CNN が登場してきました。これが ResNet と呼ばれるモデルです。
CNN の層の深さをディープにしたネットワークを DNN とも呼びます。DNN の代表的なモデルとして、VGG、GoogleNet、ResNet などを上げることができます。これらの DNN モデルの特徴についても簡単に説明します。
これらのDNN モデルでの学習においては、通常のCPUの利用だけでは非力で、GPUを利用することが必要となってきました。ましてや、スマートフォンなどのモバイル端末では、これらのモデルをインストールすることさえできません。モバイル端末でも利用可能なCNNモデルも登場してきました。その場合、モデルの学習は難しいので、画像認識や物体検出などでは学習済みのモデルを用いることになります。モバイル端末でも利用可能なネットワークモデルの代表は、MobileNetとSqueezeNetと呼ばる軽量版CNNです。これらの特徴についても、簡単に紹介します。
従来、 自然言語処理 における Deep Learning アルゴリズムと言えば、 LSTM や GRU といった RNN (Recurrent Neural Network) でした。感情分析や文脈分析などの自然言語処理などで使用されているRNN(Recurrent Neural Network)の説明は別のページで行います。RNN および LSTM モデルの説明については、こちらのページを参照ください。2017年6月、"Attention Is All You Need" という強いタイトルの論文が Google から発表され、機械翻訳のスコアを既存の RNN モデル等から大きく引き上げます。論文”Transformer: A Novel Neural Network Architecture for Language Understanding”において、RNN や CNNを使わず Attention のみを使用したニューラル機械翻訳アルゴリズム Transformer が提案されました。Transformer の説明は 別のページを参照ください。
ディープラーニングの多くのフレームワークはPython及びC++で記述されています。ニューラルネットワークの基本的構造とその実装を理解するための言語としてはPythonが理解できれば十分でしょう。そういう意味では、この領域において必須のプログラミング言語はPythonです。
なお、GoogleがGoogle Colaboratory という無料で使用できるCloud サービスを開始しました。Google Colaboratoryは、Jupyter Notebook をベースとした、Googleの仮想マシン上で動くPython実行環境です。無料であり、Googleにアカウントを登録すれば、Pythonなどのインストール等の作業に手間を取られることなく、すぐに機械学習のコードを実行することができます。GPUも無料で利用することができるので、GPUコンピューティングによる機械学習やDeep Learning等の高速化処理も可能です。Pythonなどの知識がなくても、スマホからでも実習ができます。このページでも、Google Colabで実習できるノートブックを作成して、Google Colabにアップロードしていますので、Python環境をセットアップできない方やスマホから実行したい方は是非利用して下さい。
AIや機械学習に関するページで説明されるPython コードを自分の手で実行したいと希望する方は、Googleのアカウント登録、および、GitHubのアカウントの登録をすることをお勧めします。両方とも無料で行えます。
関係する GitHub Repo は https://github.com/mashyko/deep-learning です。ご利用ください
Last updated: 2026.1.10(2018年8月20日開設)
畳み込みニューラルネットワーク(CNN)の特徴 |
パーセプトロン概念を用いた多層パーセプトロンのニューラルネットワークでは、隣接する層のすべてのニューロンが互いに結合していました。これを全結合と呼び、denseなネットワーク(fully connected)となっています。このdenseなニューラルネットワークでは、層と層の間に活性化関数が入っていても、各層のニューロンは前の層のすべてのニューロンからの信号を受け取ります。
これに対して、CNNはその名前の通り、全結合層が多層化されるのではなく、convolution layer層とpooling layer層(subsampling層ともいう)という新しい層が加わります。言い換えれば、convolution層とpooling層が交互に配置され、最終部分に全結合層が配置される多層ニューラルネットワークです。
多層パーセプトロンから構成されたニューラルネットワークの問題点は、入力情報の空間的な情報が無視されてしまうことです。入力データが画像の時、画像情報は通常、縦・横・チャンネル(あるいは、チャンネル・縦・横の形式)からなる3次元情報で与えられます。例えば、MNISTデータのケースを見れば明らかな通り、入力画像の形状は(1,28,28)ですが、全結合層に入力する場合、28x28の1次元情報に変換しました。通常の画像データは3次元なので、この操作は画像の空間的な情報を失わせることになります。空間的に近い位置にあるピクセルは似たような性質を持つ、RGBに対応する各チャンネル間には類似の傾向があるという情報を失ってしまいます。
CNNでは、こうした情報の損失を回避することができます。畳み込み層は形状を維持します。入力データが画像である場合、画像の3次元データを3次元データとして次の層に移します。CNNでは、畳み込み層の入出力データを特徴マップ(feature map)といい、入力データを入力特徴マップ、出力データを出力特徴マップと言います。
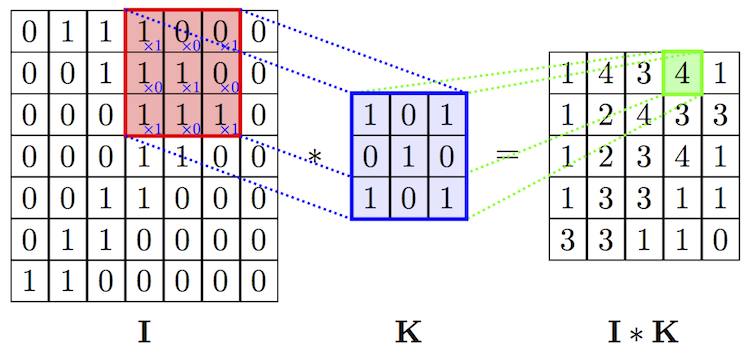
ここで、畳込みについて復習してみましょう。畳み込みの計算は少々分かり難いです。入力データ( I )が7✕7行列であり、畳み込みのカーネル(フィルター)行列( K )が3✕3行列のケースが下に描かれています。
カーネルの枠を一定間隔で入力データIの行列枠上をスライドさせます。各スライドごとに、カーネル行列の要素と入力データの対応する要素をそれぞれ乗算し、その総和をもとめて、この総和値を特徴マップ(feature maps)に移します。上の例では1x1+0x0+1x0+0x1+1x1+0x0+1x1+0x1+1x1=4と計算されています。入力データが7✕7行列であるときには、特徴マップのサイズは5✕5行列となります。次のケースは入力データが5✕5行列の場合です。カーネル行列は同じです。
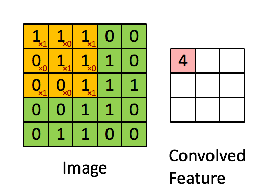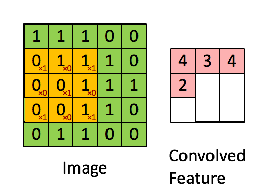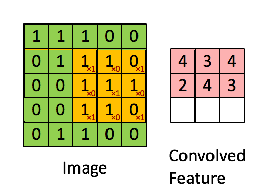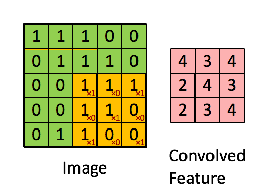
カーネル行列をスライドさせながら、各行列の各要素の乗算の総和を特徴マップに書き入れていきます。その結果、特徴マップ( S )は3✕3行列になっています。畳み込みの計算を数式で表現すると、特徴マップの(i,j)要素は \[ S(i,j) = I*K(i,j) = \Sigma_m \Sigma_n I(i+m, j+n) K(m,n) \] となります。iはカーネル行列を横にスライドさせた時のi回目のスライド、jは縦にスライドさせた時の回数です。横に3回スライドして入力行列が覆い尽くされるときは、特徴マップの次数は3となります。
max poolingとはフィルター行列で覆われた行列中の最大値をその行列の代表値にすることです。2x2フィルターによるmax poolingでは、入力データを2✕2行列ごとに覆い、2✕2行列の中の最大値を取り、その値を出力信号として送ります。この結果データサイズが縮小されます。下の図を見るとよく分かります。
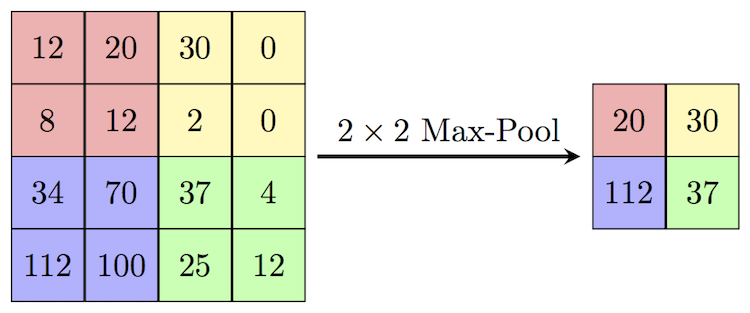
下で取り上げる代表的なCNNであるLeNetとAlexNetの構造を見ても理解できる通り、交互に並べられた畳込み層とプーリング層の後に、Classificationと呼ばれる多層パーセプトロンが配置されます。多層パーセプトロンは基本的にはすべてのユニットが結合されている構造を持つので、fully connected layersという言葉が使われています。畳込み層とプーリング層を重ねることによって入力データの各特徴がより明確に抽象化されます。こうして抽象化された各特徴を手がかりとして、最後の多層パーセプトロンの部分が入力データの分類を実行します。このことから、多層パーセプトロンの部分は分類器とも呼ばれる機能を持ちます。
1998年にLeCunたちによって提案されたCNNが最初のモデルでLeNetと呼ばれています。その構造は下の図のとおりです。
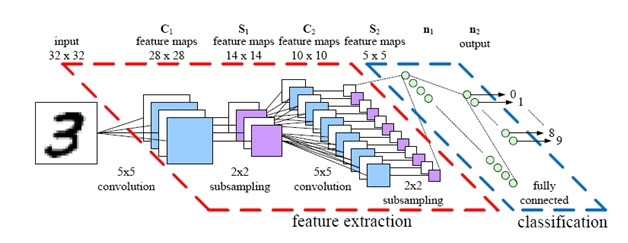
CNNで有名なLeNetの例
LeNetではcovolutional層とsubsampling層が交互に並んでいます。LeNetの図の例で、5✕5 covolutionという表示は、5行5列のフィルター行列(カーネルとも言う)で畳み込むことを意味しています。2✕2 subsamplingという表示は2✕2行列でデータサイズを縮小することを意味します。
第1層の畳み込み層で入力データ(32x32サイズ)を5x5のフィルター行列で畳み込みを行い、28x28サイズの出力特徴マップとして出力しています。この特徴マップを2x2サイズのフィルター行列でサブサンプリング(プーリング)を行い、次の畳み込み層に14x14サイズで出力します。この14x14サイズの特徴マップを5x5サイズのフィルター行列で畳み込みを行い、10x10の特徴マップとして、プーリング層に出力します。2x2フィルター行列を持つプーリング層は、5x5サイズの特徴マップを出力して、全結合層(多層パーセプトロン)に入力信号として渡されます。全結合層の出力は、活性化関数を通して、10クラスの分類機にかけられます。
その14年後、2012年にAlex Krizhevskyたち(トロント大学の研究者) が提案したモデルがAlexNet(筆頭著者の名から)と呼ばれるCNNです。covolutional層とpooling層が交互に並んでいます。
このAlexNetの例では、5個のcovolutional層と3個のpooling層が存在します。"stride of 4"という表示は4列おきに、フィルター行列を入力データ上でスライドさせることを意味します。ネットワークの最終部分では、分類識別のために、3種類の全結合層(Fully Connected layer: FC)が配置されて、最後の層からはsoftmax関数(活性化関数)を通して、1000クラスに対する確率分布の出力が出てきます。これは、ImageNetで採用されている画像の1000クラス分類に対応させるためです。
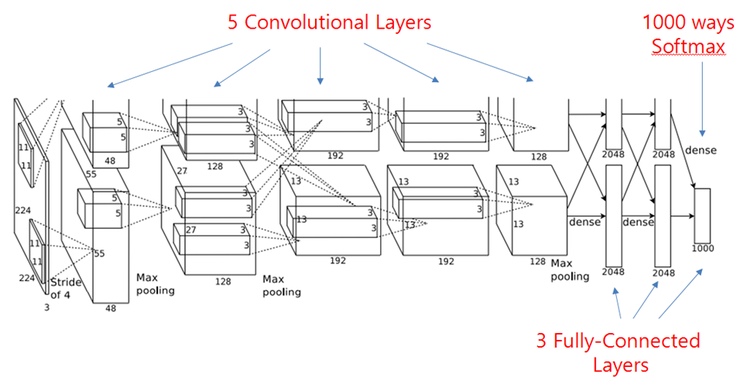
CNNで有名なAlexNetの例
畳み込み層が二つに分割されている理由は、GPUの性能に制約を受けているためです。入力画像はImageNetからなので、そのサイズは(3, 224, 224)です。詳しくは、論文 "ImageNet Classification with Deep Convolutional Neural Networks" を読んでください。
| Layer | Filter_size | Stride | Output_size |
|---|---|---|---|
| input | 224, 224, 3 | ||
| convolution | 11, 11 | 4, 4 | 55, 55, 96 |
| maxpooling | 3, 3 | 2, 2 | 27, 27, 96 |
| convolution | 5, 5 | 1, 1 | 13, 13, 256 |
| maxpooling | 3, 3 | 2, 2 | 13, 13, 256 | convolution | 3, 3 | 1, 1 | 13, 13, 384 | convolution | 3, 3 | 1, 1 | 13, 13, 384 | convolution | 3, 3 | 1, 1 | 13, 13, 256 |
| maxpooling | 3, 3 | 2, 2 | 6, 6, 256 |
| fully_connected | 4096 | ||
| fully_connected | 4096 | ||
| fully_connected | 1000 |
多層パーセプトロン・モデルとCNN モデルの違い |
多層パーセプトロンネットワークの拡張版であるニューラルネットワークとCNNとの違いはどこにあるのでしょうか?多層パーセプトロンネットワークは、前層の出力信号がすべてのパーセプトロンに着信される全結合パーセプトロン(fully connected: dense :affine と呼ばれる)の層とその出力信号を入力とする活性化関数の層を2層、3層、そして多層に繋げたネットワークです。この場合、入力信号は1次元配列に変換されて、データの形状が無視されてしまいます。
上でも触れた通り、MNIST データの識別では、手書きデータは (1, 28, 28) 次元、つまり、1チャネル、縦28ピクセル、横28ピクセルの画像データですが、これを784要素からなる1次元配列に変換して、全結合層に入力します。画像は3次元データですが、これを1次元データに変換してしまうため、画像の空間的特徴が失われます。空間的に近いところにあるピクセルは類似しているとか、各RGBチャネルの間にはある相関があるという特徴が喪失します。
畳み込みニューラルネットワークはこれらの欠陥を改善するために開発されました。畳み込み演算という処理を組み込んだ畳み込み層が登場します。この畳み込み層は、入力データの形状を維持しまします。例えば、3次元データであれば、3次元の状態を維持して次の層に出力します。畳み込み層の入出力データを特徴マップと言います。さらに、プーリング層という概念が提案されます。プーリングとは、縦・横方向の空間を縮小させる演算です。例えば、2行2列の領域を一つの要素に集約するような操作をします。この改善を受けて、CNNは、従来のニューラルネットワークに畳み込み層+活性化層+プーリング層の多層化された構造を組み込んでいます。
一般の画像データのようにRGBチャネル数が3 になるケースでは、画像データの畳み込みでは畳み込みフィルターの数もチャネル数と同じ数になる必要があります。各チャネルに対応する畳み込みフィルターのサイズは任意です。画像データが(3, 28, 28)である時、畳み込みフィルターが5行5列であるならば、チャネル数と同じく3種類の5x5フィルターが必要です。つまり、畳み込みフィルターの次数は(3, 5, 5)となります。この畳み込み演算を行うと、2次元配列のデータが出力されます。(各チャネルごとに畳み込みをして、その結果を合計・加算します。)例えば、2次元配列(10, 10)のデータが作成されます。チャネル数は1となります。
これでは、データの空間的特徴が失われる可能性があるので、多数の異なる畳み込みフィルターを用いて、畳み込み演算をすることが一つの有効な方法なります。(3, 5, 5)次数の異なる畳み込みフィルターを10種類用いると、10種類の出力特徴マップが出力されて、特徴マップの次数は(10, 10, 10)となります。つまり、チャネル数10の(10,10)配列の特徴マップが出力されます。この場合、畳み込みフィルターの次数は(10, 3, 5, 5) となっています。
3次元データを多次元配列で表現するとき、通常は、(channel, height, width)の順に並べて表記します。単純に、順序を逆にして、width x height x channel と表記するときもあります。チャネル数がC、縦の高さH、横幅Wであるとき、(C, H, W)と書きます。(W, H, C)と表記することもあります。フィルターの場合も同様に書きます。 フィルターのチャネル数がFC、縦の高さFH、横幅FWであるとき、(FC, FH, FW)と書きます。この時の出力の特徴マップのサイズを(1, OH, OW)と表記します。2次元配列の特徴マップが出力されます。畳み込みのパディング=Pd、ストライド=Srと評すると、関係式
OH = (H + 2Pd - FH)/Sr + 1が成立します。詳しくは、斎藤康毅著『ゼロから作るDeep Learning』(オライリー・ジャパン社)などの参考書を参照してください。
FN種類の(FC, FH, FW)サイズの畳み込みフィルターを使用するとき、FN個の特徴マップが出力されます。つまり、出力特徴マップのサイズは(FN, OH, OW)となります。畳み込みフィルターのサイズは(FN, FC, FH, FW) となります。
勾配降下法と誤差逆伝播法(backward propagation) |
CNNで画像や音声データを識別するためには、大量の既存データを用いて、モデルの損失関数を最小化する重みパラメータの値を見出す、機械学習と呼ばれる作業が必須です。機械学習とは、モデルの予測結果がデータのラベルと合致するような重みパラメータの最適解を見出す学習問題になります。この最適化問題を解くためにいくつかの手法が提案されています。
CNNにおける層が深くなればなるほど、機械学習で学習すべき重みパラメータの数も急速に増大します。最近のDNNであるYOLO、SSDなどでは層の深さが数百程度になっており、数十万個の重みパラメータの訓練が必要とされています。これらの訓練問題を短時間で実現することは、CPUを搭載したPCの能力をはるかに超えます。ここでは、この実際的な問題に触れることはせず、理論上の最適化手法について説明します。
微分法が発見されて以降、最も有名な最適化手法は、勾配降下法(Gradient Descent method)と呼ばれる方法です。谷底に短時間でたどり着く方法は、最も傾斜がきつい稜線を降り続けることです。原理的には、これと同じ方法を適用したものです。ただし、途中でアップダウンがある可能性は否定できません。人間の目はこのことを容易に発見しますが、機械にはできません。このことも考慮する必要があります。
例を用いて、勾配降下法について説明します。2変数\( x_1, x_2 \)の関数\( f \)が
\[ f(x_1, x_2) = (x_1 - 1)^2 + (x_2 - 2)^2 \]であるとします。このとき、明らかに、この関数の最小値は 0 で、この最小値を取る座標(最小化点)は
\[ (x_1, x_2) = (1, 2) \]であることがわかります。この最小化点を勾配降下法で探索することを考えます。まず最初に、探索点の初期設定を行います。例えば、探索の初期点を\( (x_1^0, x_2^0) = (0, 0) \)としましょう。探索の方向とステップ幅を定めます。探索方向を関数の勾配方向 (gradient) に取ります。ステップ幅を\( \eta \)とします(これを学習率と言います)。この設定のもとでは、最小化点を探索する計算は
\[ x_1 = x_1^0 - \eta \frac{\partial f(x_1^0, x_2^0)}{\partial x_1} \\ x_2 = x_2^0 - \eta \frac{\partial f(x_1^0,x_2^0)}{\partial x_2} \]となります。最小化点に到達するまで、この計算を繰り返します。このプログラムは、このColabで実行できます。
これ以降の説明はテクニカルな話になります。勾配降下法および逆伝播法のPython 実装についての説明はこのページで説明します。興味のある方はそちらを参考にしてください。テクニカルな説明が必要ない方は、以下の説明に進んで下さい。
画像識別に活用されているCNNモデル:VGG、GoogLeNet、ResNet |
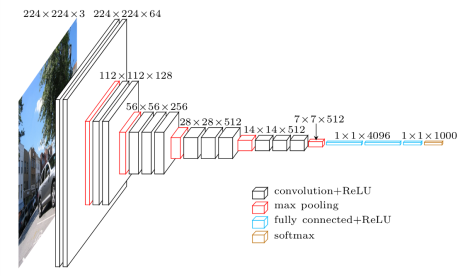
VGGモデルは、畳み込み層とプーリング層から構成されたCNNで、層の深さを16層、または、19層にしたモデルです。オックスフォード大学のVGG(Visual Geometry Group)という研究グループが開発した、AlexNetの進化系です。原論文は、こちらからダウンロードできます。非常に小さな3x3 畳み込みフィルターを使って、ネットワークの深さを16から19に増加させることにより、識別の精度を改善している。この小さいフィルターを持つ畳み込み層を2〜4回連続して重ね、それをプーリング層でサイズを半分にすることを繰り返し行う構造が特徴です。2014年のILSVRCコンペでは2位に終わったが(1位は後述のGoogLeNet)、とてもシンプルなアーキテクチャであることが実用に向いています。
入力画像は 224x224 RGB画像です。最初の3x3畳み込み層でのフィルターのチャネル数(深さ)は64で(conv3-64と表記)、max-pooling ごとに2倍になり、128、256、526と増加します。出力は1x1000次元配列です。VGG16 ネットワークは以下の順序で繋がっています。
| 順番 | 層 | 出力サイズ |
|---|---|---|
| 1 | conv3-64 | 224x224x64 |
| 2 | conv3-64 | 224x224x64 |
| - | max-pool | 112x112x128 |
| 3 | conv3-128 | 112x124x128 |
| 4 | conv3-128 | 112x124x128 |
| 5 | conv3-128 | 112x124x128 |
| - | max-pool | 56x56x256 |
| 6 | conv3-256 | 56x56x256 |
| 7 | conv3-256 | 56x56x256 |
| 8 | conv3-256 | 56x56x256 |
| - | max-pool | 28x28x516 |
| 8 | conv3-512 | 28x28x516 |
| 9 | conv3-512 | 28x28x516 |
| 10 | conv3-512 | 28x28x516 |
| - | max-pool | 14x14x516 |
| 11 | conv3-512 | 14x14x516 |
| 12 | conv3-512 | 14x14x516 |
| 13 | conv3-512 | 14x14x516 |
| - | max-pool | 7x7x516 |
| 14 | FC-4096 | 1x1x4096 |
| 15 | FC-4096 | 1x1x4096 |
| 16 | FC-1000 | 1x1x1000 |
| - | softmax | 1x1x1000 |
FC-4096 は並列次数4096 のFully Connected layer の略です。図に描くとこうなります。
GoogLeNetは,2014年のILSVRCの優勝モデルです。(なお、7年間にわたりAI研究を牽引してきたILSVRCは、2017年大会をもって終了しました。)基本的ネットワーク構造はCNNと同じですが、ネットワークの構造が縦方向だけでなく、横方向に深さを持っていることです。つまり、GoogLeNetの一番の特徴は,複数の畳み込み層やpooling層から構成されるInceptionモジュールと呼ばれる小さなネットワークを作成して、これを通常の畳み込み層のように重ねていくことで1つの大きなCNNを作り上げていることです。原論文は、こちらからダウンロードできます。下にInception モジュールの例を図示します。

Inception モジュールを組み込んだネットワーク構造は以下のように構成されています。
| 順番 | 層 | 出力サイズ |
|---|---|---|
| 1 | conv7 | 112x112x64 |
| 2 | max-pooling3 | 56x56x64 |
| 3 | conv3 | 56x56x192 |
| 4 | max-pooling3 | 28x28x192 |
| 5 | inception | 28x28x256 |
| 6 | inception | 28x28x480 |
| 7 | max-pooling3 | 14x14x480 |
| 8 | inception | 14x14x512 |
| 9 | inception | 14x14x512 |
| 10 | inception | 14x14x512 |
| 11 | inception | 14x14x528 |
| 12 | inception | 14x14x832 |
| 13 | max-pooling3 | 7x7x832 |
| 14 | inception | 7x7x832 |
| 15 | inception | 7x7x1024 |
| 16 | avg-pooling7 | 1x1x1024 |
| 17 | dropout(40%) | 1x1x1024 |
| 18 | linear | 1x1x1000 |
| 19 | sofmax | 1x1x1000 |
ここで、conv3 は3x3サイズのフィルターを持つ畳み込み層であることを意味します。112x112x64 は出力サイズを表現します。
Inception モジュールで5×5の畳み込み層を3×3の畳み込み層を2つ重ねたものに置き換えるように改良したモデルはInception-V2と呼ばれます。
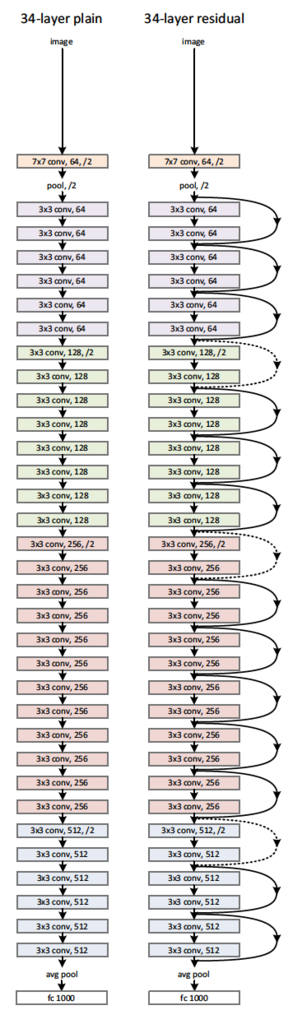
ResNet は Microsoft社のKaiming Heのグループにより提案され、2015年のILSVRCで優勝したCNNモデルです。それまでのネットワークでは層を深くしすぎると性能が落ちるという問題があったが、それを「残差学習構造」によって解決した。残差学習構造は、ある層への入力をバイパスし層をまたいで奥の層へ入力してしまうというもので、これにより勾配の消失や発散を防止し、超多層のネットワークを実現している。ネットワークの深さも152層の深さ(前年優勝のGoogLeNetでも22層)を実現しています。原論文は、こちらからダウンロードできます。
下に残差学習構造(residual learning: shortcut connection)の例を図示します。
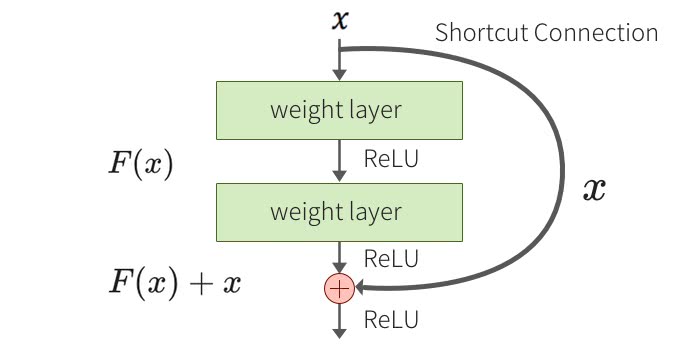
Resnetの構成要素の概略図(residual learning: building block)
この図で、weight layer とは畳み込み層を意味します。こうした残差学習構造を導入することにより、層を深くしても効率的に学習することが可能になります。ResNet はこの残差学習ブロックをカスケード状に接続して、152層のネットワークに構成したものとなっています。152層のネットワークを図に描くことは難しいので、34層構造の概略図を示します。
画像識別などで活用されているディープな畳み込みネットワークのモデルは、上記のVGG 、GoogLeNet、 ResNet に代表されます。これらのネットワークモデルを実装するためのPython フレームワークが提供されています。TensorFlow 、 Pytorch 、Theano 、 Chainer などが代表的なOSSライブラリです。このうち、Tensorflow が最も広範に使用されているライブラリだと思われます。また、TensorFlow 、 Theano をbackend とするPython APIとして Keras というライブラリも存在します。Deep Learning の初心者にとっては、この Keras が扱いやすいです。Keras と Tensorflow のインストール、および、 Keras + Tensorflow を用いた画像識別の実際については、Kerasを用いたディープラーニングのページを参照ください。Pytorch を用いた画像識別の実際については、Pytorchを用いたディープラーニングのページを参照ください。
モバイル機器に利用できるCNN モデル:MobileNet と Squeezenet |
最初に、MobileNet について説明します。 MobileNetはDepthwise Separable Convolutionを用いることで、通常のCNNと比べて軽いネットワークを構築することができた。また2つのハイパーパラメータである、width multiplierとresolution multiplierを導入することで、latencyとaccuracyを調節することができた。この技術を用いることで、性能や応答時間に制限があるモバイル上のアプリケーションなどにおいても認識や分類モデルへの応用が可能になっています。原論文はここからダウンロードできます。
下に通常の畳み込みとDepthwise Separable Convolutionとを比較した例を図示します。

Depthwise Separable Convolutionの例
たとえば、112 x 112 x 32という入力に対して、通常のCNNでは、3 x 3 x 32 x 64のカーネルを用いて畳み込みを行い、112 x 112 x 64の出力をするケースを考えると、Depthwise Separable Convolutionでは、まず3 x 3 x 32のフィルタを用いて、depthwise convolutionを行う。この出力は、112 x 112 x 32のままである。次に、1 x 1 x 32 x 64のフィルタを用いて、pointwise convolutionを行う。この出力は56 x 56 x 64になります。MobileNetの改良版MobileNet-V2の原論文はここにあります。
ネットワークの構成は以下のようになっています。全ての畳み込み層の後にはBatchNormとReLU関数が接続していますが、図では省略されています。s1とs2はstride1、2の略です。全体で28層からなります。
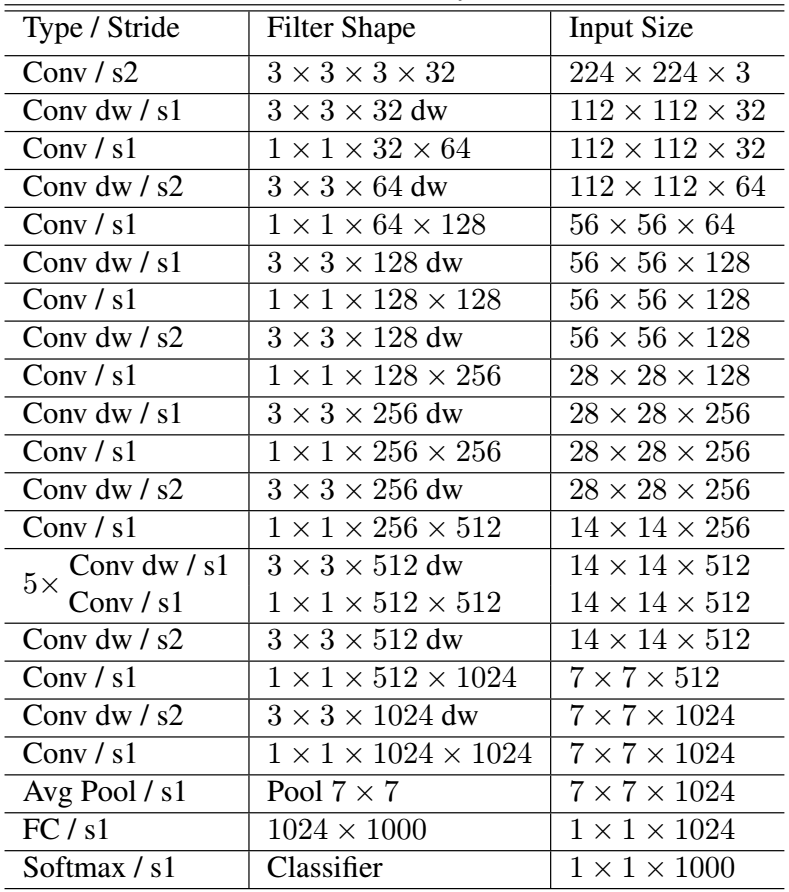
MobileNet のネットワーク構成図
MobileNet は VGG16 に比較して、同等の精度を持ちながらも、サイズは32分の1で、処理速度は23分の1になると報告されています。
次に、SqueezeNetについて説明します。SqueezeNetでは、Convolutionレイヤーを、SqueezeレイヤーとExpandレイヤーの2つの組み合わせで置き換えます。Squeezeレイヤーは1x1のConvolutionであり、出力チャネル数が3です。Expandレイヤーは、1x1x4の畳み込み層と3x3x4 の畳み込み層をパラレルに並べて、ReLU 関数に出力しています。これをFire モジュールと言います。原論文はここからダウンロードできます。下にsqueeze層とexand 層から構成されたFire モジュールの例を原論文から引用しました。
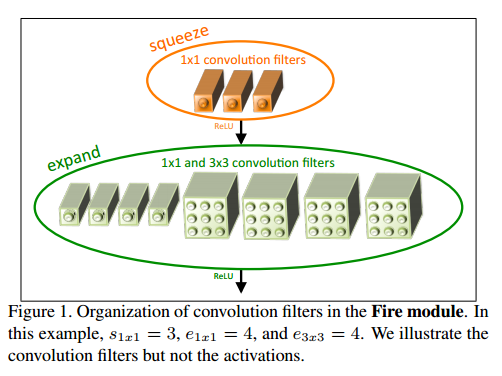
Fire モジュールの例
SqueezeNetのネットワークアーキテクチャは下の図の通りです。
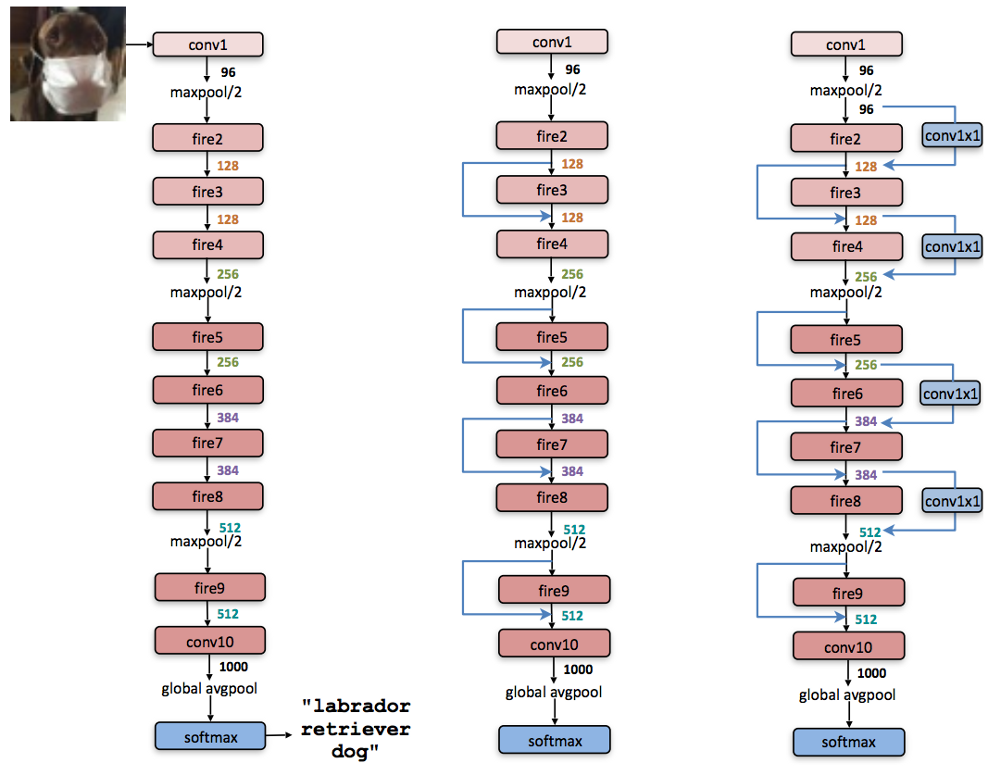
SqueezeNet のネットワーク構成図
左の図は最も単純なネットワークで、中央の図はFireモジュールの間にバイパスを挟んでいます。右側の図は、Fireモジュールの間にバイパスと畳み込み層を挟んでいる複雑なネットワークになっています。
CNN の利用はすでにスマートフォンなどのモバイル端末でもお馴染みになっています。モバイル端末にCNNモデルを利用できるようなライブラリとフレームワークが開発されています。Google社が提供するTensorFlowの軽量版を活用すると、iOSおよびAndroidのスマートフォンに画像認識、物体検出、言語分析などの機能を持つDeep Learning用のモデルがインストールできます。詳しくは、このページを参照ください。Apple社もiOS端末向けに、機械学習ライブラリCore ML 2 を提供しています。詳しくは、このページを参照ください。
Cloud型GPUコンピューティングの利用 |
GPUは元々、グラフィック用の専用のボードとして利用されてきました。最近では、グラフィックス処理だけでなく、数値計算の処理にも利用されるようになってきた。GPUは並列的な数値演算を高速に行うことができるので、そのパワーを機械学習でも活用することになってきました。
機械学習では、例えば、Deep Learning でのモデル学習では、大量の数値演算、とりわけ、行列積の計算が必要です。大量の並列的演算はGPUが得意とする分野です。このことの故に、Deep Learning でのモデル学習で、GPUを利用することによって、CPUを使用する場合に比較して驚くべきほどの高速化を達成できます。CPUだけでは1ヶ月以上もかかる計算でも、最近のGPUで数日で処理を達成してしまいます。
GPUを主に生産しているメーカーは NVIDIA と AMDA の2社です。両者のGPUとも、汎用の数値計算には活用できますが、Deep Learning での学習演算に親和性があるのはNVIDIA社製のGPUだと言われています。その理由は、NVIDIA社が提供するCUDAというフレームワークによります。
通常使用のPCでは、メモリが足りず処理できなかったり、1試行ごとに数十分~数時間待などの回避するために、クラウド上のデータ分析のGPUをレンタルするという方法もあります。IBM Cloud、Amazon AWS、Google Cloud Platform、そしてMicrosoft Azure 等のCloud版GPUサービスが提供されています。最近、GoogleがGoogle Colaboratory という無料で使用できるCloud サービスを開始しました。
Google Colaboratoryは、Jupyter Notebook をベースとした、Googleの仮想マシン上で動くPython実行環境です。無料であり、Googleアカウントを登録すれば、インストール等の作業に手間を取られることなく、すぐに機械学習のコードを実行することができます。ソースコードや実行結果はGoogleドライブに保存されるため、共有・同時編集することが容易に行えます。GPUも無料で利用することができるので、GPUコンピューティングによる機械学習やDeep Learning等の高速化処理も可能です。
Google Colabの公式サイトはhttps://colab.research.google.com/です。使用の方法についての説明は、公式ページのチュートリアルを参照ください。TensorFlow、PyTorch、DetecctronなどのGithub RepoからもGoogle Colabに接続してGPUを用いたコードが実行できるようになってきています。GitHub とも統合されているので、作成したNotebookをGoogle Driveに保存できるだけではなく、GitHubのRepoにも保存できます。AIのPython API と Google Colabの使用法のページにも簡単な説明があります。